Technical description of the application, programming models, platform and infrastructure
Platform and infrastructure
This tool is run using Python 3.9.6 and Apache Spark 3.5.0. Installation methods vary depending on your operating system, please refer to the linked websites for more information. The sole additional python library needed is MatPlotLib which can be installed with pip: pip install matplotlib
Programming models
The most important model used is within PySpark, and it's a combination of Resilient Distributed Dataset (RDD) and Data Frame (DF). Combining both offers the widest range of possibilities to analyse big data.
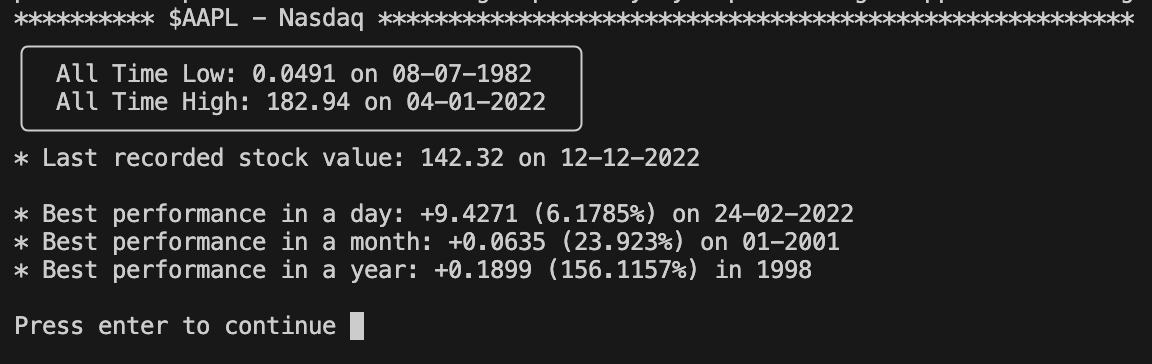
The application
The code is organised like a standard python module, with a main file that is the only being executed by the user. The remaining files are sperated according to their functionalities, with three folders for: All-stock performance on a certain period of time, market analysis during historical events and stock-specific analysis.